Paper Reading: SEER (Structured Reasoning and Explanation via RL)

原文 https://arxiv.org/abs/2401.13246
提出了一个关于
- 生成 证明假说 $h$ 的 entailment tree / 完成 结构化推理 任务
的
- 强化学习训练算法。
Task Formulation 任务设置
输入
- $X = \{x_1, x_2, ..., x_n\}$ — premises, 已知的背景知识、前提的集合
- 一个假说 $h$ — hypothesis
输出
一个结构化的解释 (A structured explanation),通常是一棵蕴含树 (Entailment Tree) $T$.
- 叶子节点: $X$ 里边挑选出来的相关事实,也就是几个 $X$ 的元素
- 中间节点:通过子节点推理得出的中间结论 — Intermediate conclusions
- 其实应该可以是个 图?反正得有个根,入度是0的节点(根)只能有一个
- 根:最终的假说 $h$
强化学习配置 RL Config
Overview
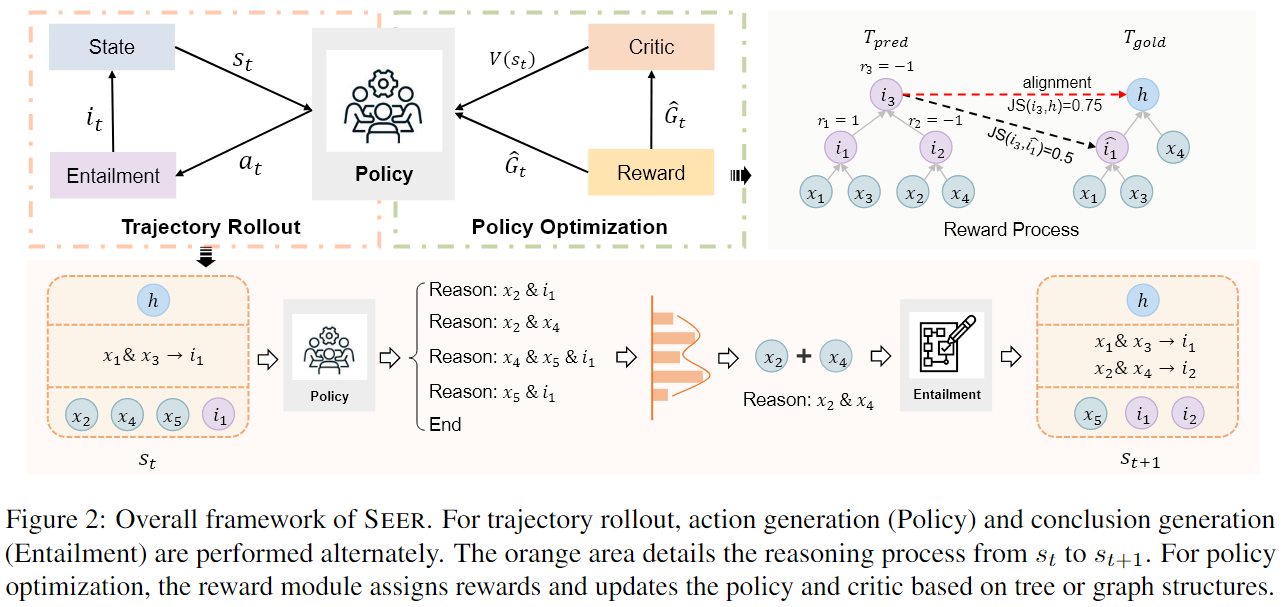
- 轨迹展开 (Trajectory Rollout): 模型(也就是“策略 Policy”)根据当前状态,生成一个完整的推理步骤序列(称为一个“轨迹”)。
- 策略优化 (Policy Optimization): 生成轨迹后,系统会给这个轨迹中的每一步打分(奖励 Reward),然后用这些分数来更新模型,让模型在下一次生成轨迹时,更倾向于生成分数高的(也就是更正确的)推理步骤。
State
$$ s_t = \{h, P_t, C_t\} $$- $P_t$: 已经完成的证明,例如
x1, x2 -> i1 - $C_t$: 候选句子集 (Candidate sentences)。这是当前可以用来进行下一步推理的“材料库”,它包括所有还没用过的事实,以及我们已经推导出的所有中间结论。
i1, i2, …+x3, x4, ...
Action
在当前状态 $s_t$ 下可以做出的决策
两种类型
-
Reason: <premises>-
agent 从 候选句子集合 $C_t$ 中生成出一个或者多个句子作为前提(premises)
-
调用 entailment module 蕴涵模块 生成一个中间结论 intermediate
-
such as: 选出
x1,x2来获取i1→ 整个action被称为Reason: x1, x2再来个例子:
Reason: x5, i1
-
-
End推理已经结束,即某个中间步骤已经 等同于 或者 足够接近于 假设 $h$
我们结束整棵树(并且返回)
Action带来的问题:space太大了
因为 Reason: <premises> 中的 <premises> 空间是 $C_t$ 中的任意多个前提的组合
- (闭包, closure, kleene star) $2^n$
- 之前的工作: $n\choose 2$ ,通过每次只选2个
- 所以 prompt 一个LLM来进行 生成:
Reason: x? & x? & x?
Policy
生成 action (prompted??)
Entailment Module
在reason action生成之后,生成一个 entailment 结果
- 问题: grad pass到这了?
- 为什么不和policy合体?
Trajectory处理 + Reward
首先生成了一个 tau trajectory, $\tau$ 为 $\tau_1,\dots,\tau_n$
然后 $\tau$ 的最后一步 $\tau_n$ 一定是 End
所以我们假设 $\tau_{n-1}$ 一定是模型模拟 hypothesis 的步骤
我们期望
$$ \tau_{n-1}\approx h $$
奖励是用来告诉代理它上一步的动作“做得好不好”的信号。这是SEER的一个关键创新点,它设计了一个细粒度的奖励函数:
- 奖励 = +1 (正确步骤): 如果生成的推理步骤,在与标准答案(ground-truth tree)对比后,被认为是完全正确的。
- 奖励 = -0.5 (冗余步骤): 如果生成的步骤本身逻辑上可能没问题,但它对于最终构建出最佳的推理树是多余的、没用的。这种步骤会受到轻微的惩罚,而不是像错误步骤那样被重罚。这鼓励模型进行必要的探索,而不会因为一点小错就完全否定探索行为。
- 奖励 = -1 (错误步骤): 如果生成的步骤是完全错误的。