


Programming Project #5 (proj5)
COMPSCI 180 Intro to Computer Vision and Computational Photography
Chuyan Zhou
This webpage uses the Typora Academic theme of markdown files.
Part A
0. Setup
2 Stages
We first use 3 prompts to let the model generate output images. Here are images and captions displayed below, with different inference steps:
5 steps (i.e.
num_inference_steps=5):Size: 64px * 64px (Stage 1)

an oil painting of
a snowy mountain village
a man wearing a hat 
a rocket ship Size: 256px * 256px (Stage 2)

an oil painting of a snowy mountain village 
a man wearing a hat 
a rocket ship
20 steps:
Stage 1:

an oil painting of a
snowy mountain village
a man wearing a hat 
a rocket ship Stage 2:
an oil painting of a
snowy mountain village
a man wearing a hat 
a rocket ship
100 steps:
Stage 1:

an oil painting of
a snowy mountain village
a man wearing a hat 
a rocket ship Stage 2:

an oil painting of a
snowy mountain village
a man wearing a hat 
a rocket ship
Reflection on the generation
We find that for 5 steps, the outputs are not so clear, specifically, the noise added are not removed so completely. We can observe lots of noisy dots in the generated images. The generated feature is also not so clear.
For 20 steps, the noise is removed, and the generated image starts to be decent. The generated images are quite close to the text prompts.
For 100 steps, the generated images are quite clear and the features are well generated, also closer to the text prompts.
Seed
We use the seed SEED=42 in this project part.
1. Sampling Loops
1.1 Implementing the Forward Process
A key part of diffusion is the forward process, which takes a clean image and adds noise to it.
which is equivalent to an equation giving
That is, given a clean image
We run the forward process on the test image with




1.2 Classical Denoising
From the noisy images above in different time steps, we try using Gaussian blurring filters to denoise them. Respectively, the kernel size for 3,5,7, and the sigma is 1.5,2.5,3.5. Here we show the trials of denoising using this classical way.



We can see the Gaussian filters denoise the images so poorly: the original noises are not eliminated, while main features and shapes of the Campanile is blurred.
1.3 One-step Denoising
Now, we try to recover
Here, the expression of
where
The one-step denoising results (the original image, the noisy image, and the estimate of the original image) are shown below.






We have seen a much better denoising performance in 1.3 i.e. one-step denoising. But when
1.4 Iterative Denoising
The diffusion model by an iterative denoising can solve the problem in 1.3 that for larger
The formula for iterative denoising to estimate the previous step of forwarding (i.e. the next iterated step in denoising) is
where
Given








1.5 Diffusion Model Sampling
In this part, we use another important use of diffusion models other than denoising: sampling from the real-image manifold. We feed the iterative denoising function with randomly (drawn from Gaussian) generated noises, using the prompt "a high quality photo" as a "null" prompt as a way to let the model simply do unconditional generation.
Here are 5 images from sampling from the "null" prompt:





These images are reasonable, but not too clear nor spectacular. We can enhance this by CFG in the next section.
1.6 Classifier-free Guidance
For a noise or generally, input image, we have the generation conditioned on some prompts. For the same input without conditioning, the model can estimate an unconditional noise denoted as
The estimate of the noise, from above, is expressed as
where
Basically, this can be seen as a guidance, i.e. a push (
If we set
Here are 5 images from sampling from the "null" prompt, with CFG at scale





The result images are much better.
1.7 Image-to-Image Translation
In this part, we follow SDEdit algorithm to transform one image (our inputs) to another with some conditioning. This can be done with inputting the iterative denoising pipeline with our input images, and set a t (or an equivalent index of the strided time steps i.e. i_start a.k.a. noise level), which is the forward step. t is seen as a claimed level of the noises added to the input, i.e. how much "noise" should the model "reduce" into "the original image". The smaller the noise level is, the more t is, and the more the image is denoised (edited).
We use given noise levels [1, 3, 5,7, 10, 20] and the "null" prompt i.e. "a high quality photo" as the conditioning. Results are shown below:
Result 1: Berkeley Campanile






Result 2: Self-selected image 1: kusa.png







Result 3: Self-selected image 2: pien.png







1.7.1 Editing Hand-Drawn and Web Images
Same as above, we pick some images from the web & hand-drawn and feed them into the translation.
Result 1: Web image








Result 2: Hand-drawn image 1: A Cruise








Result 3: Hand-drawn image 2: A Lemon








1.7.2 Inpainting
Now, we implement a hole-filling (inpainting) algorithm. We use the same iterative denoising pipeline, but with a mask
where
Result 1: Berkeley Campanile



Result 2: Self-selected image 1 (Pagoda)




Result 3: Self-selected image 2 (Pien)




1.7.3 Text-Conditional Image-to-image Translation
In this part, we do the same as in 1.7 and 1.7.1. But we use a text prompt as the conditioning. The text prompt is "a rocket ship". The results are shown below.
Result 1: Berkeley Campanile






Result 2: Self-selected image 1: kusa.png






Result 3: Self-selected image 2: pien.png






1.8 Visual Anagrams
In this part, we use the iterative denoising pipeline to generate visual anagrams (according to this research), which is basically a image that shows a feature when watched ordinarily without being transformed, and another feature when watched upside down.
We can implement this by modifying the noise estimate. One estimate from the noised image now i.e.
The results are shown below.
Result 1


Result 2


Result 3


1.9 Hybrid Images
In this section, we perform the hybrid image generation, which is to generate an image that shows one feature in low frequency (far away / blurredly) and another feature in high frequency (closely / clearly), based on this paper (Factorized Diffusion). We estimate the noise by these formulas:
where
We use a kernel size of 33 and sigma of 2 as is recommended in the project spec for the LP filter as a Gaussian filter, and the HP filter is to find the difference between the original image and the LP-filtered image, i.e. the difference between identity and the LP filter. The results are shown below.
I used the text encoder instead of predetermined .pth embeddings to get the embeddings for my DIY prompts as in Result 2 and 3.
Result 1 Low pass: a lithograph of a skull High pass: a lithograph of waterfalls

Result 2 Low pass: a salmon sushi nigiri High pass: a sitting orange cat with a white belly
Result 3 Low pass: a photo of the Ayers rock High pass: a photo of a dog lying on stomach

2. Bells & Whistles
I used the text encoder instead of predetermined
.pthembeddings to get the embeddings for my DIY prompts as above.
2.1 A logo for the CS180 course
I designed a logo for this course, CS180, using the model stage 1 above, and also upsampled it to a higher resolution using stage 2 of the model.
The logo is a pixelated bear holding a camera, ready to taking a photo.
The logo is shown below:
Part B
1. Training a Single-Step Denoising UNet
Given a noisy image
1.1 Implementing the UNet
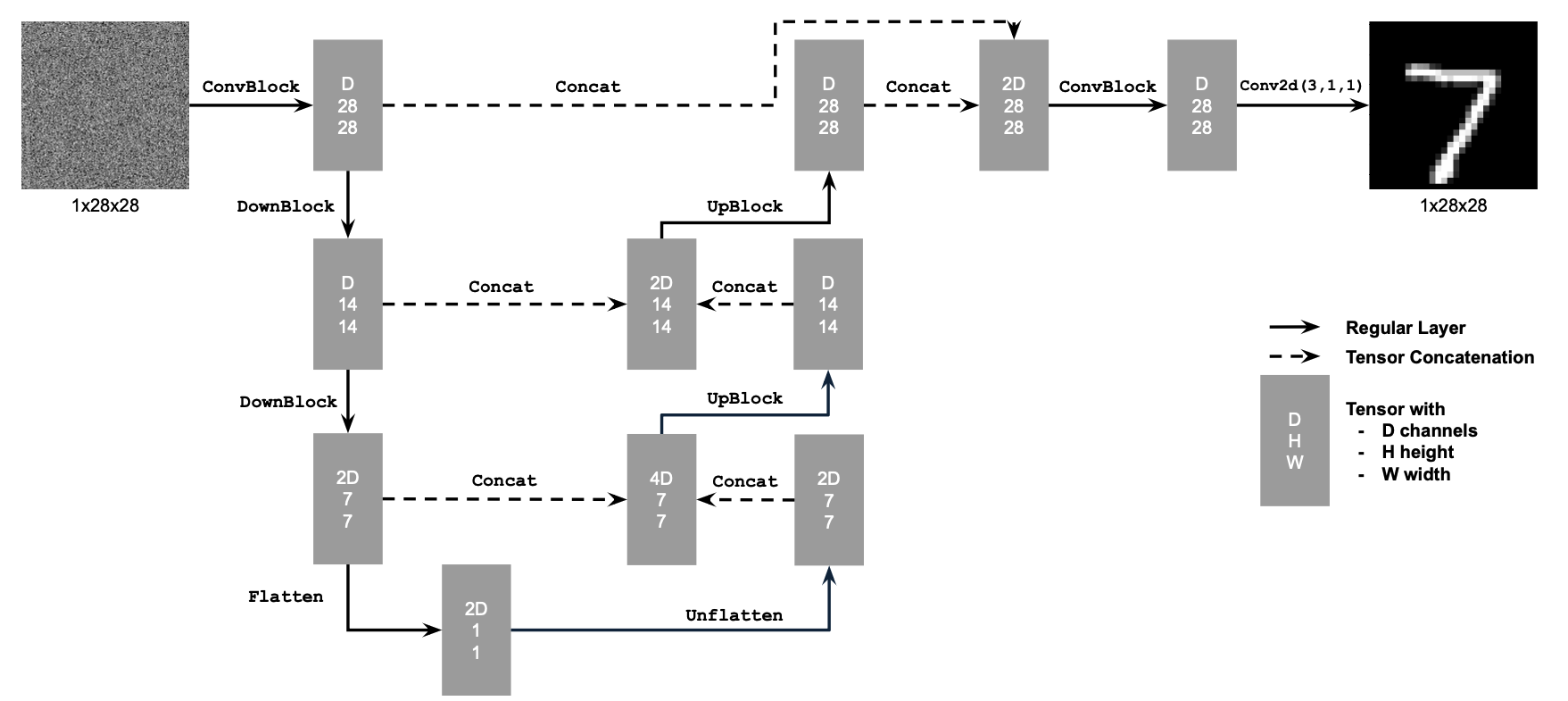
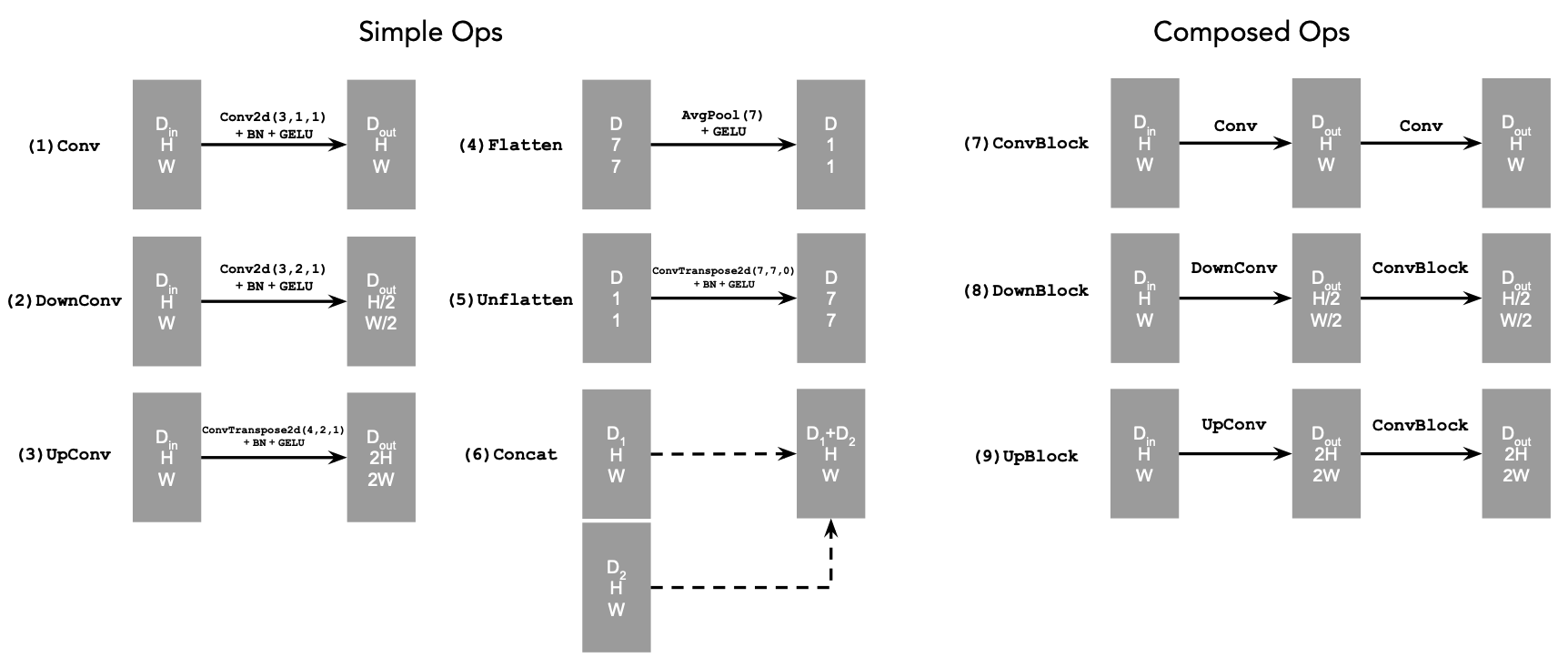
We implement an unconditional UNet as shown in the graph above, where operation blocks mentioned above are:
1.2 Using the UNet to Train a Denoiser
To train the unconditional UNet denoiser, we dynamically (not with pre-computed noises) generate
We show varying levels of noise on MNIST digits, with

1.2.1 Training
Now, we train the denoiser with
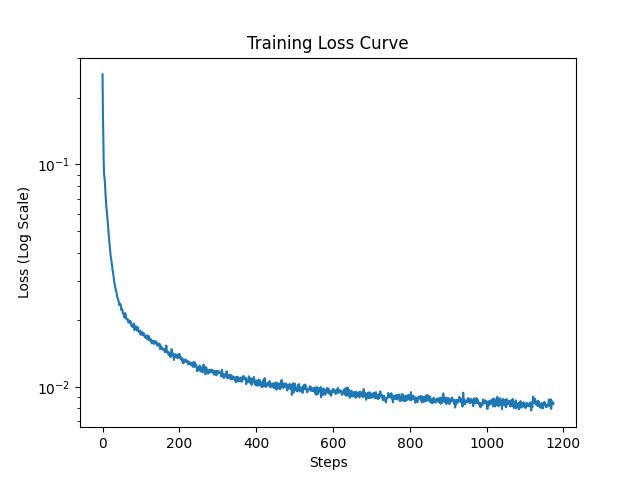
The training loss curve is shown below.
We visualize denoised results on the test set at the end of training.


1.2.2 OOD Testing
Though the denoiser is trained where

2. Training a Diffusion Model
Now, we are to implement DDPM. We now want the UNet to predict the noise instead of the clean image, i.e. the model is
From (2) we know
for a certain time step
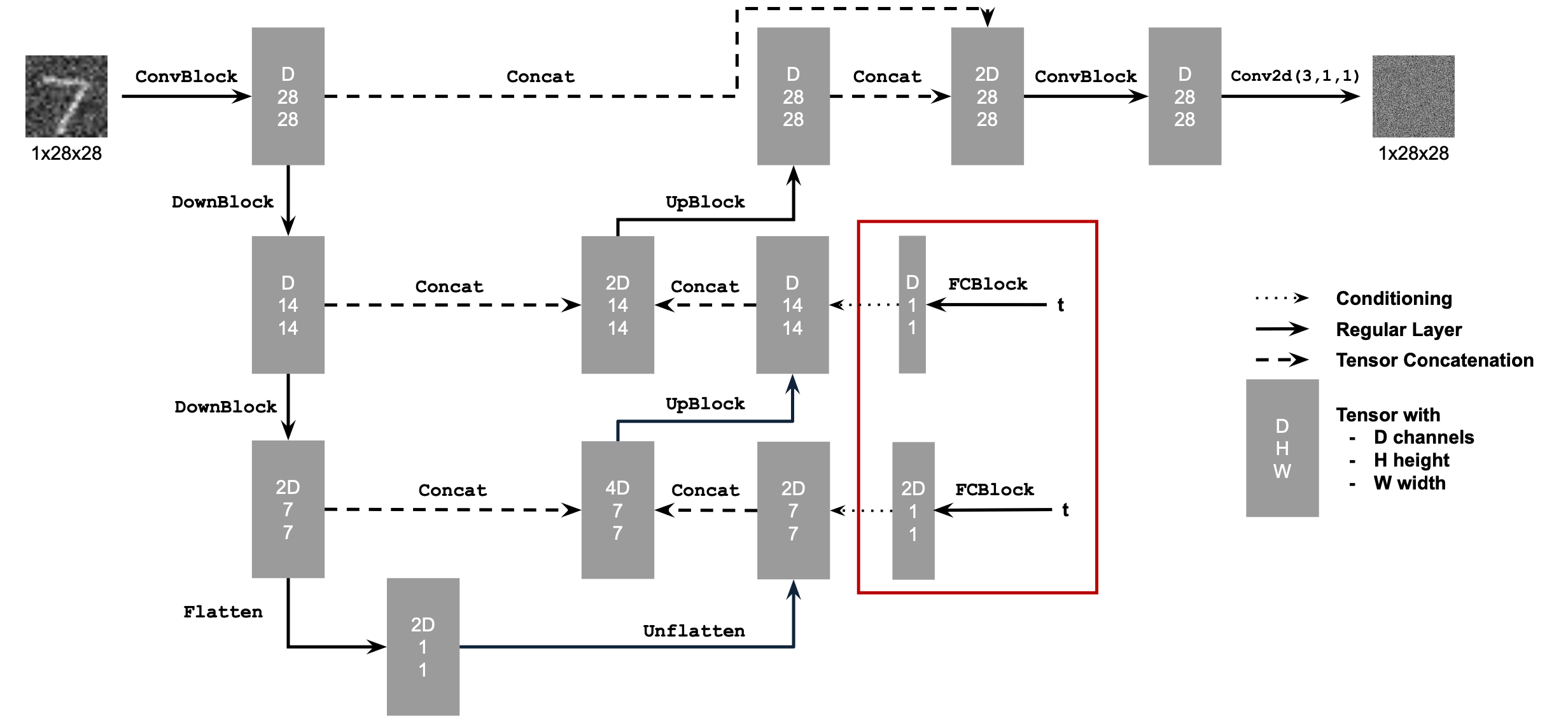
where the FCBlock is
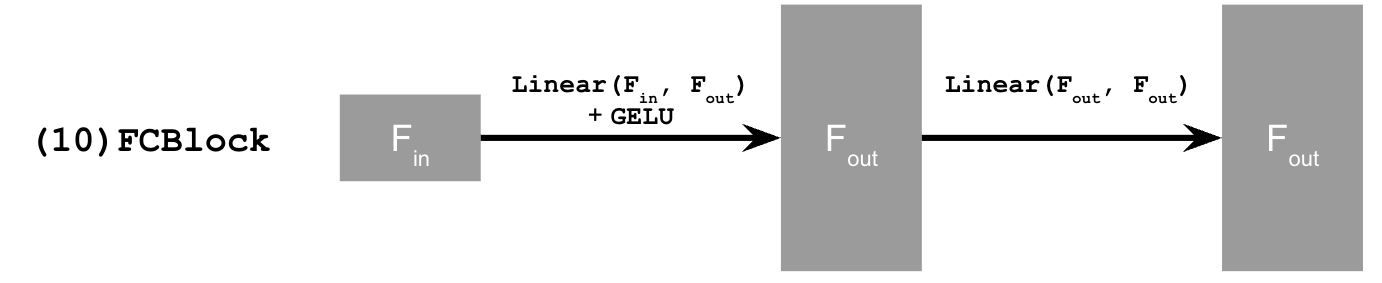
In DDPM, we also have a noise schedule which is a list of
2.1 Adding Time Conditioning to UNet
We add an encoded time conditioning using broadcasting to the results of an UpBlock and an Unflatten layer as shown in the graph above.
Now, the objective with time conditioning is
where
2.2 Training the Time-Conditional DDPM
The training algorithm is as follows:

In the implementation, we train the DDPM on MNIST (same in parts below) with batch size 128, 20 epochs,
The training loss curve is shown below.
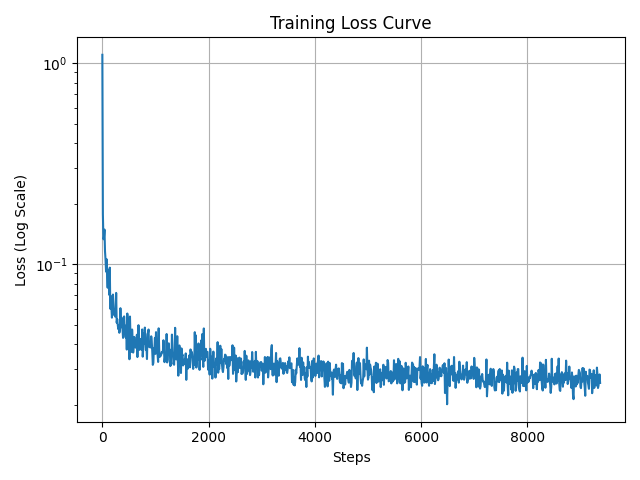
2.3 Sampling from the Time-Conditional DDPM
Following the sampling algorithm of DDPM as follows:

we can now sample from the model. We show sampling results after the 5th and 20th epoch.




2.4 Adding Class-Conditioning to UNet
We want the DDPM generate images given a specific class. To modify the UNet architecture, we can now add 2 more FCBlocks and feed them both with the one-hot class vectors which are masked to 0 with a probability
When we are adding time conditioning, we now multiply the pre-addition hiddens elementwisely with the outputs of the FCBlocks passing the class signals.
We use a same set of hyperparameters as in 2.2. The class-conditional training algorithm is as follows:

The training loss curve is shown below.
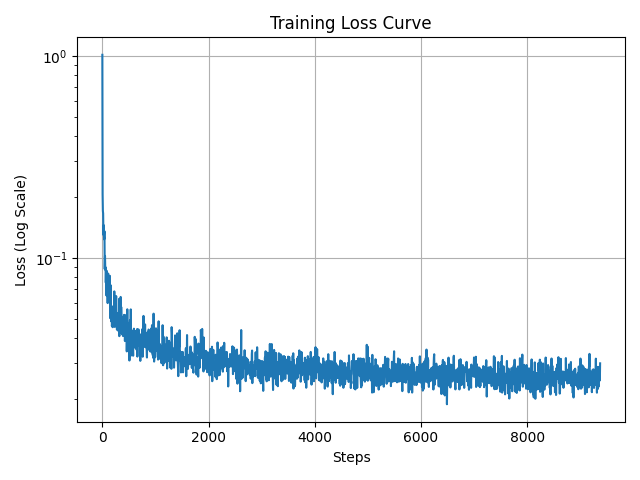
2.5 Sampling from the Class-Conditional DDPM
With class conditioning, we should also use classifier-free guidance mentioned in Part A. We use CFG with a guidance scale

The sampling results are shown below. We can see the class signals are received very well.




3. Bells & Whistles: Improving Time-conditional UNet Architecture
For ease of explanation and implementation, our UNet architecture above is pretty simple.
I added skip connections (shortcuts) in ConvBlock, DownBlock and Upblock, which is to add a plainly convoluted input (working as the residual a.k.a. the "identity") to the output of the block. We train with the same set of hyperparameters as in 2.2.
The improved UNet can achieve a better test loss (0.02820390514746497) than the original (0.02956294636183147).
The training loss curve is shown below.
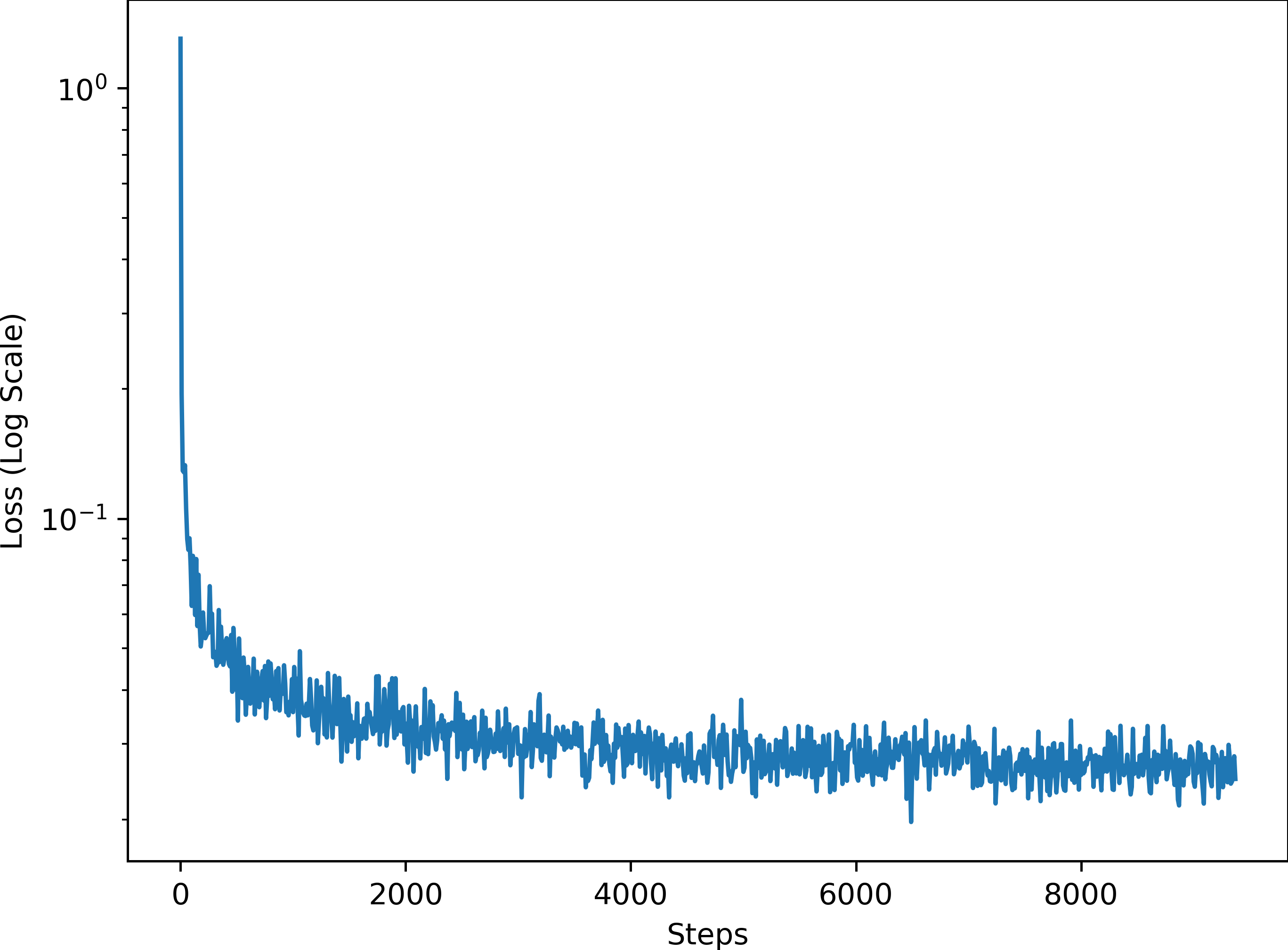
The sampling results are shown below.




4. Bells & Whistles: Rectified Flow
Instead of DDPM, we now implement a novel SOTA framework named Rectified Flow.
4.1 Overview
Rectified Flow (RF) is a generative modeling method, which tries to transport data from source distribution
The overall objective is to align the velocity estimate (using the UNet, denoted as
For a general case when
We define the interpolation path as
where
and we can also add the class conditioning where
We can see, we want the path as straight as possible.
4.2 Training
For an RF, the objective is listed above, which is to minimize over the whole dataset and also over all times.
However, as we all know, we can only estimate the integral
For a time-conditional RF, using the Monte Carlo method, we can estimate the objective (loss) by
where
For a class-conditional RF, the estimate is
where
The loss can be regarded as a L2 loss between the predicted velocity and the real displacement too. The algorithm is shown below:

4.3 Sampling
For a RF, we build an ODE to sample. The ODE setup for a time-conditional RF is
and we want
Similarly, this integral is also not directly computable. We can use ODE solver (solving methods) to estimate this as well.

The methods can be Euler's method or RK45, and we implement the former as a simple but working one.
The estimate for
where
For a class-conditional RF, the framework is similar, but we specify the class
and the estimate
4.4 Implementation Detail and Results
I implemented two kinds of RF (time/class-conditional) based on the structure of DDPM.
I used the time-conditional UNet for the time-conditional RF, and the class-conditional UNet for the class-conditional one. The architecture of this core model remains same as in DDPM.
Beta schedules (the list) is no longer needed, but the number of timesteps as a hyperparameter is still necessary for the forward and sampling methods to generate an estimate.
For the class-conditional RF, the CFG is also slightly changed to guide the conditioned velocity estimate instead of the noise estimate, from the unconditioned counterpart:
We train with the same set of hyperparameters as in 2.2. The training and testing loss are higher than those in DDPM training, but the generated (sampled) images are fairly good and unnoised.
Results of Time-Conditional RF
The training loss curve for the time-conditional RF is shown below.
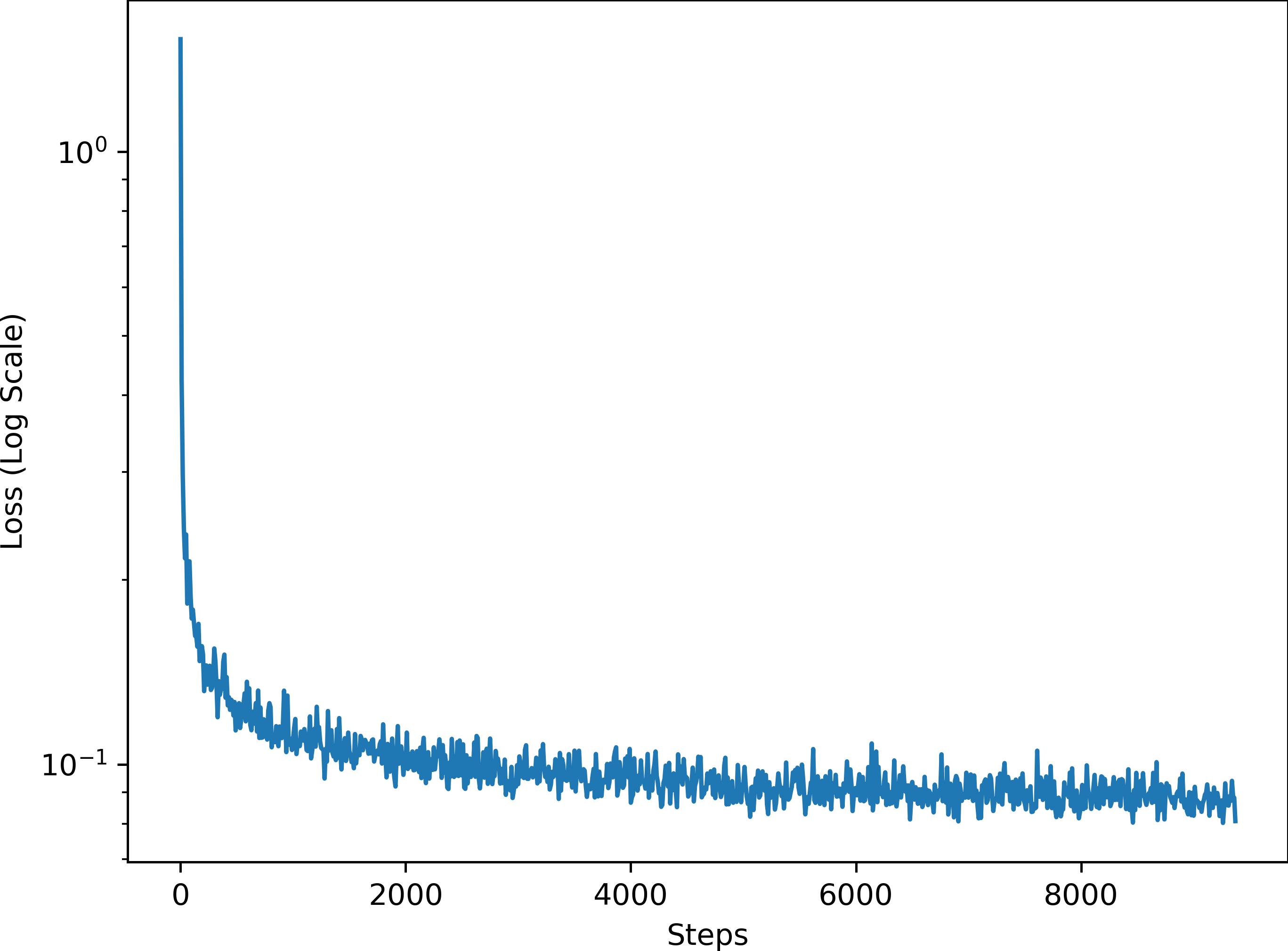
The sampling results for the time-conditional RF are shown below.




Results of Class-Conditional RF
The training loss curve for the class-conditional RF is shown below.
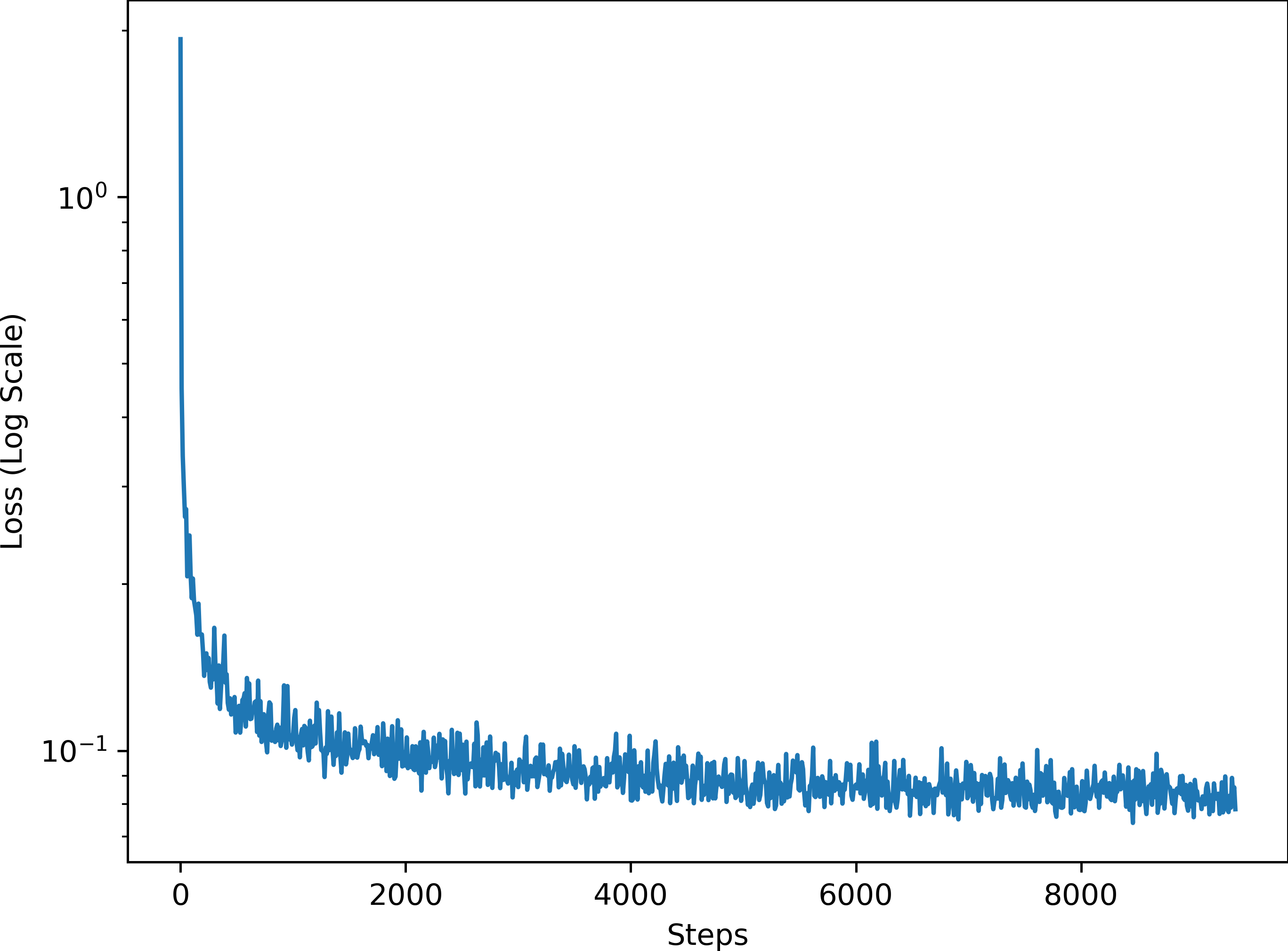
The sampling results for the class-conditional RF are shown below.



5. Bells & Whistles: Sampling Gifs
I implemented the GIF generating code, and the generated Gifss are juxtaposed with static images in every section above and below.