
Programming Project #1 (proj1)
COMPSCI 180 Intro to Computer Vision and Computational Photography
Chuyan Zhou
This webpage uses the Typora Newsprint theme of markdown files.
Overview
Sergei Mikhailovich Prokudin-Gorskii (1863-1944) [Сергей Михайлович Прокудин-Горский, to his Russian friends] was a man well ahead of his time. Convinced, as early as 1907, that color photography was the wave of the future, he won Tzar's special permission to travel across the vast Russian Empire and take color photographs of everything he saw including the only color portrait of Leo Tolstoy. And he really photographed everything: people, buildings, landscapes, railroads, bridges... thousands of color pictures! His idea was simple: record three exposures of every scene onto a glass plate using a red, a green, and a blue filter. Never mind that there was no way to print color photographs until much later -- he envisioned special projectors to be installed in "multimedia" classrooms all across Russia where the children would be able to learn about their vast country. Alas, his plans never materialized: he left Russia in 1918, right after the revolution, never to return again. Luckily, his RGB glass plate negatives, capturing the last years of the Russian Empire, survived and were purchased in 1948 by the Library of Congress. The LoC has recently digitized the negatives and made them available on-line.
The goal of this assignment is to take the digitized Prokudin-Gorskii glass plate images and, using image processing techniques, automatically produce a color image with as few visual artifacts as possible. In order to do this, you will need to extract the three color channel images, place them on top of each other, and align them so that they form a single RGB color image.
Step 1: Preprocessing
Every image provided is a digitized glass plate image vertically arranged, with one example, the original cathedral.jpg listed as follows:

Given the images, i.e. digitized glass plate images, black and white borders appear constantly in every one of them. Because evaluating the similarity metrics of two image channels may be influenced by these borders, we can do some preprocessing to avoid this consequence. First, we directly cut the original rectangle-shaped image into 3 equal parts (shapes of which are ensured to be the same), BGR top to bottom; and we just crop the B/G/R channel subimages by 10% of the height of each subimage. After this procedure, no borders are visible given the project data.
This is actually proved effective. For example, the cropped version aligned with NCC exhaustive search of monastery.jpg:

is significantly visibly better than the uncropped version:

Step 2: Exhaustive Search
We align Green/Red channels to the Blue channel, and we will displace these channels by the roll function in the NumPy library.
2.1 Algorithm Overview
To align one image (G/R channel) to another (B channel), i.e. to displace (roll) one image while another works as a fixed reference, the naive idea is to try a range of displacement vectors (tuples) of the first image (we call img1), evaluate every possible displacement with a metric, and then choose the best one w.r.t. the optimum of the metric, which may be maximum or minimum.
Some metrics are given in the description, which we first implement for the baseline method.
The range here is set as
2.2 Sum of Squared Differences (SSD)
For the image img1 and the reference img2, denote them as img1 as
The SSD is the sum of all squared differences of every pair of pixels in the same position in the two images, i.e.
where every
We search for the minimum SSD to find the best alignment.
Notice the MSE/Euclid distance metrics are just variants (in this project), because if we want to minimize these metrics, the minimizers will be the same as the SSD version.
2.3 Normalized Cross-Correlation (NCC)
The other metric given is NCC, which is the dot product of the two images flattened and then normalized, i.e.
where
2.4 Results for JPEGs
With exhaustive search implemented, we are able to find decent displacements for the images. These are the results and their displacement vectors.


SSD and NCC metrics turn out to have the same displacement results for these 3 images.
2.5 Problem met
For TIFF images given, the file sizes are too large for exhaustive search to process in a reasonable time span. We have to find some new methods to reduce the time complexity here.
Step 3: Image Pyramid
3.1 Algorithm Overview
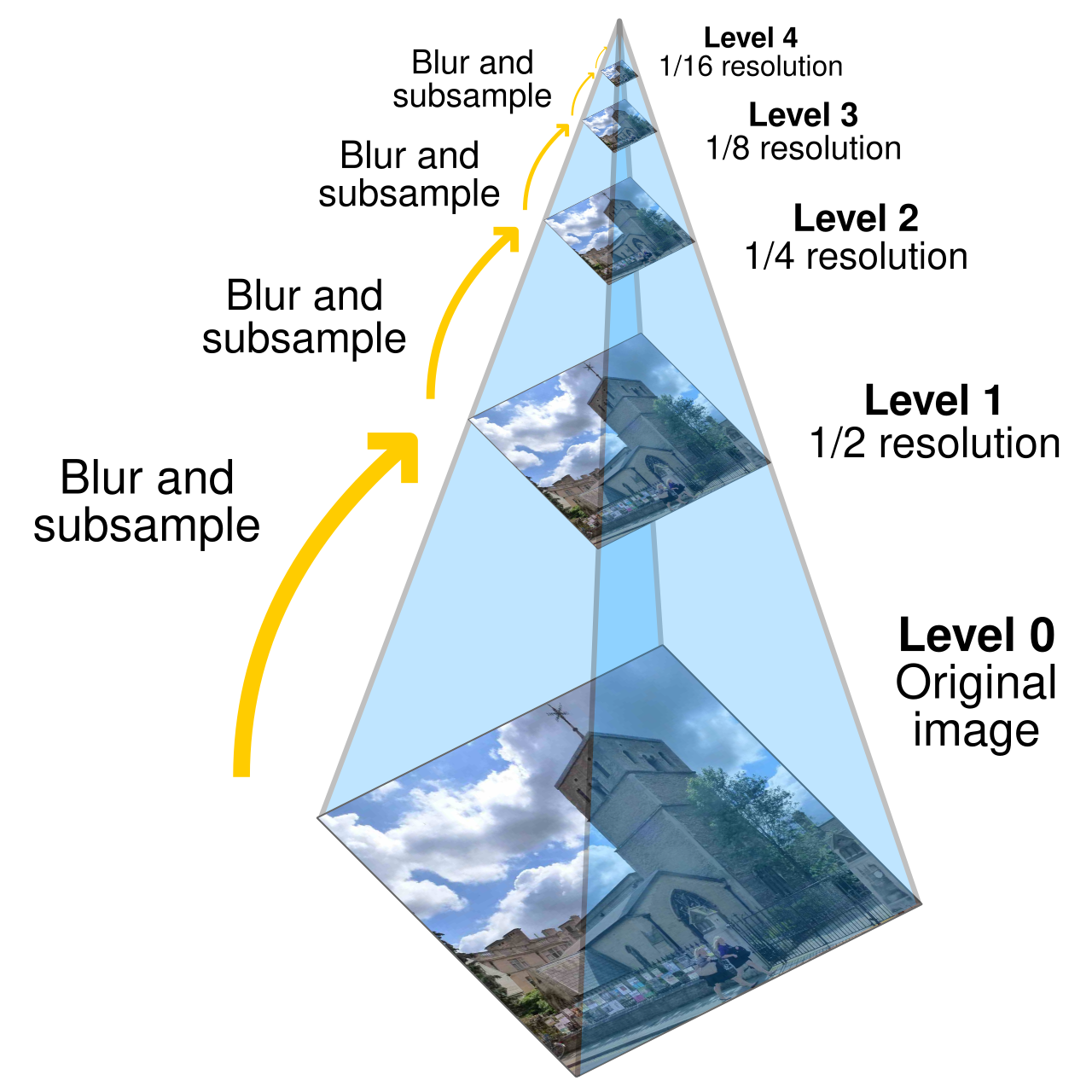
Image pyramid algorithm is to process one image or multiple images by first processing on the low resolution levels, and then use the scaled processing actions to process relatively high resolution levels until processing the original image.
Different levels, with level 0 as the original image, are placed in order and processed in order. We call the ordered list or stack a pyramid. The pyramid top is the smallest scale.
In the scenario here, i.e. image alignment, we build a pyramid for img1 i.e. img2 i.e.
To leverage the image pyramid to search for the displacement, we first use exhaustive search for the
Then, repeat: roll the current level image in 2x scale displacement from last level; exhaustively search for a best displacement for the current level image that has been rolled; add new displacement to the 2x-scaled displacement; save the updated displacement (and go into the next level where we apply the 2x displacement in the current level), until there is no next level, namely, we reach the original image.
Notice that because we choose 2x as the scaling factor, so every time we go to the next level, there will be one new pixel added back which is filled in the gap of the two pixels in current level. Hence, the searching space can be compressed to
We can still use the metric above, and the result will not change because the overall searching spaces are equivalent.
3.2 Results for all
Because of the file sizes are too large, we post the jpeg-compressed images of all tiffs here.
NCC and SSD lead to same displacement results. Also, in the TIFF-processing stage, the NCC method will run slower than SSD. The SSD pyramid will take about 38s, while the NCC takes about 1min.

Red: (124, 13)

Red: (176, 37)

Red: (178, 13)

Red: (58, -4)
Red: (89, 23)

Red: (98, -206)

Red: (87, 32)

Red: (3, 2)

Red: (140, -27)

Red: (6, 3)

Red: (108, 36)

Red: (112, 11)

Red: (12, 3)

Red: (111, 12)
3.3 The Problem of Emir
With just searching the displacements over cropped images, and just SSD/NCC metrics, the emir.tif is not aligned well, because the images to be matched do not actually have the same brightness values (they are different color channels). We can balance the brightness values or use some other metrics & methods.
Step 4: Cleverer Metrics
We use the metrics introduced below combined with the image pyramid method to try to align the emir's image correctly.
4.1 Mutual Information (MI)
We can evaluate the MI metric of two images. In probability theory and information theory, the mutual information given two discrete random variables
where
For two images mentioned before as img1 and img2, or
where
For the probability symbols,
Because the mutual information quantifies the "amount of information" obtained about one variable when observing another variable, it is better when the mutual information is higher. So we maximize the MI metric for the best displacement of G/R with B as reference.
4.1.1 The Emir w.r.t. MI

Green: (49, 23) Red: (106, 40)
We can see the channels align correctly now under this metric.
4.1.2 Running Time
Though MI is an effective metric, it is much more time-consuming than provided SSD or NCC metrics, with the same parameter set of the pyramid method. For the emir, it takes about 40s to find the displacement under MI, but only about 3~5s to find the displacement under SSD/NCC.
4.2 Structural Similarity Index Measure (SSIM)
For the images
where
where
In the most common case,
We can thus simplify the SSIM metric as
We maximize the simplified SSIM metric to find the best alignment, because it evaluates the similarity between two images.
In application, because human eyes perceive an image in a localized way (Saccadic Eye Movement), so we find the means and variances of a localized part (a window with a uniform filter). We first convolute the image through the filter, and then find the overall mean value of the convoluted image.
4.2.1 The Emir w.r.t. SSIM

Green: (50, 23) Red: (105, 40)
Though the displacement is slightly different with the MI one, we can see the channels align correctly now under this metric.
4.2.2 Running Time
It takes about 30s to run, which is better than MI and still slower than SSD/NCC.
Step 5: Edge Detection
Edge detection algorithms can also used to solve the problem of emir. We implement the method that first detect the edges of three channels, and then align the edges, output the displacements to the original image and finally roll the original image by the displacements created by the edge alignment.
We align the edge images by the image pyramid speed-up method and the SSD metric, so this can be seen as another kind of preprocessing or feature engineering of images fed into searching methods.
5.1 Canny Edge Detection
The Canny Algorithm for edge detection is a renowned algorithm with merits such as high accuracy and high resolution of edges detected.
5.1.1 Algorithm Overview
The Canny edge detection is divided in 4 steps in order.
Use the Gaussian filter to smooth the image
Use the Sobel operator as a filter to estimate the gradients of the image
where the root and the arctan are elementwise. The gradients are defined as
Non-maximum suppression, which is to generate the edge from the gradient matrix by setting all zero to non-maximum pixels around one pixel along the max-gradient direction.
Set low and high thresholds for gradients. Gradients higher than the high threshold will be seen as edges, those lower than the low threshold will be seen as non-edges. Those in between will be seen as edges only if there are 2 higher-than-threshold gradient pixels around.
Once these steps are complete, we can use these the edge images (final-processed
5.1.2 Result
The result is shown as:

Green: (49, 24) Red: (107, 40)
The edges detected is shown as follows:



5.2 Sobel Edge Detection
5.2.1 Algorithm Overview
This algorithm, though much simpler than the last one, can also generate good edge detection results for us to align the channels.
This involves using the Sobel operator mentioned above to find
5.2.2 Result
Because this algorithm is relatively simple, the detected edges here appear rougher than the Canny's result.
The result is shown as:

Green: (49, 24) Red: (106, 41)
The edges detected is shown as follows:


